Python搭建自动化框架
14 7 月, 2020
- 给框架分层,我一般把它分为以下几个层次,分层先建文件夹(包),然后再写逻辑层次感稍微好一点,也方便记忆。
- 根据所需搭建自动化脚本框架,一般需要什么就配置什么,比如你需要写一个配置文件来存放路径或者打开的浏览器及网站等信息,目的是为了方便修改和维护。

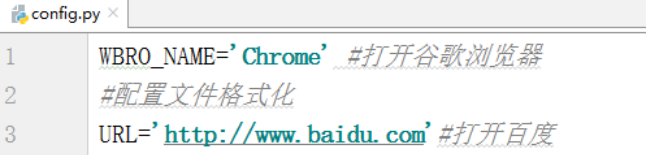
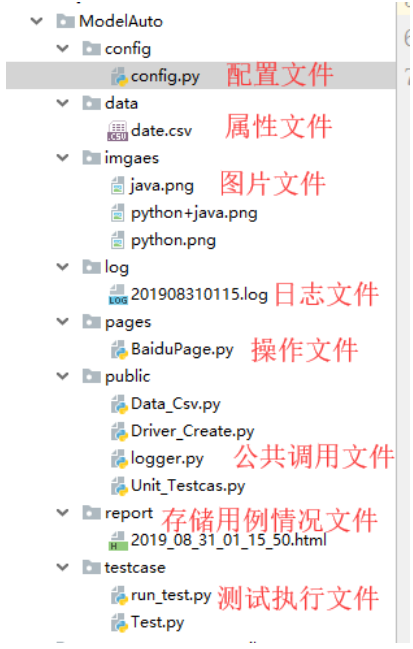
1、文件config包中创建config.py用来存放浏览器和路径
WBRO_NAME='Chrome' #打开谷歌浏览器
#配置文件格式化
URL='http://www.baidu.com'#打开百度
FileURL='E:\workspace\ModelAuto\data\date.csv' #打开date.csv文件
Run_FileURl='E://workspace//ModelAuto//testcase//'#用于找文件路径
Run_FileURlRep='E://workspace//ModelAuto//report//'#用于存放用例报告的位置
2、public包中创建Driver_Create.py文件判断浏览器
from selenium import webdriver#导入webdriver用于driver
from ModelAuto.public.logger import Logger
logger = Logger(logger="SeleniumDriver").getlog() # 日志文件
from ModelAuto.config import config #导入自己写的配置文件来判断浏览器
class DriverCreate:
def __init__(self):
self.driver = None
@staticmethod
def Driver_Creat():
try:
logger.info("打开浏览器");
if config.WBRO_NAME=='Chrome':#判断浏览器
driver=webdriver.Chrome()#谷歌
elif config.WBRO_NAME=='Firefox':#火狐
driver=webdriver.Firefox()
elif config.WBRO_NAME=='IE':#IE
driver=webdriver.Ie()
else:
logger.info("这样的浏览器不存在");
driver=None
except Exception as e:
logger.info('浏览器打开失败', e)
return driver #返回driver
3、public包中创建Unit_Testcas.py文件用来执行开始或结束setUp和tearDown方法
import unittest #导入unittest包用于类继承
from ModelAuto.config import config #导入配置文件
from ModelAuto.public.Driver_Create import DriverCreate #导入浏览器模块
class UnnitTest(unittest.TestCase):#继承 TestCase
def setUp(self):#首先执行的方法
self.driver=DriverCreate.Driver_Creat()#调用DriverCreate模块判断浏览器
# 用来代替 self.driver=webdriver.Chrome()
self.driver.get(config.URL)#打开网页地址导入config模块中用URL地址
#config.URL用来代替self.driver.get('网址')
self.driver.maximize_window()#窗口最大化
def tearDown(self):#退出执行的方法
self.driver.quit()#退出浏览器
4、在pages包中创建BaiduPage.py文件用来做操作(动作)
class BaiduPages:
#定义BaiduPages用于测试方法(操作)
def __init__(self,driver):#格式driver参数用来接收UnnitTest模块中传过来的driver
self.driver=driver
def news(self):
self.driver.find_element_by_link_text('新闻').click()#点击新闻链接的方法
def link(self):
self.driver.find_element_by_link_text('财经').click()
def kw(self,keyword):#在百度搜索框中输入内容的方法接收keyword值
self.driver.find_element_by_id('kw').send_keys(keyword)
def su(self):
self.driver.find_element_by_id('su').click()#点击一下百度搜索
def baidusousuo(self,keyword):#输入和搜索,他们需要组合
self.kw(keyword)
self.su()
5、在data包中创建date.py文件用来存放传的参数值(属性值)
name # 属性值 python java python+java
6、在public包中创建Date_Csv.py文件用来读取内容
import csv #读取date文件中的值需要导入csv模块
from ModelAuto.config import config
def readfile():#定义readfile()方法来读取内容
fp=open(config.FileURL,'r')#打开date.csv文件,为了防止不必要的错误需用绝对路径
date_csv=csv.DictReader(fp)#读取data文中的的内容用date_csv存起来,读取出来的内容是元组存起来的
# print(date_csv)
datelist=[]#所以定义一个列表把它装起来(存起来)
for data in date_csv:#遍历列表
if date_csv.line_num==1:#判断是否是第一行,是第一行跳过
continue#跳过
else:
datelist.append(data)#把遍历出来的元组用列表存起来
# print(datelist)
fp.close()#关闭打开的文件
return datelist#返回列表
def getkeyword(n):#定义属性取值的方法传个参数n
listall=readfile()#新定义一个listall等于readfile()中返回的列表值
return listall[n]['name']#返回第n个值的值,根据name来识别
# readfile()
for i in range(0, len(readfile()), 1): # 遍历readfile()方法中读取到的内容
print(getkeyword(i))
7、testcase包中创建Test.py文件,用来完成测试动作并生成测试图片
from ModelAuto.public.Unit_Testcas import UnnitTest#导入public包中的UnnitTest模块
from ModelAuto.pages.BaiduPage import BaiduPages#导入pages中的BaiduPage用来传self.driver
from ModelAuto.public.Data_Csv import readfile,getkeyword #可以用*代替
from ModelAuto.public.logger import Logger
logger = Logger(logger="SeleniumDriver").getlog()
# import unittest #导入系统自带的unittest 这个模块这里用不到因为继承了 UnnitTest这个模块中具备了 unittest
import time#导入时间模块
class Test(UnnitTest):#Test继承了 UnnitTest
def setUp(self):#格式化一下参数,没次执行时再执行一下setUp的方法把self.driver传过去,
# 启动一下 UnnitTest.setUp(self)中的方法
UnnitTest.setUp(self)# UnnitTest模块中setUp(self)方法
self.d=BaiduPages(self.driver)# 定义成全局变量,把driver传到BaiduPages中
def test_Test(self):
# setUp()方法中进行测试前的初始化工作,teardown()方法中执行测试后的清除工作,它们都是TestCase中的方法
for i in range(0, len(readfile()), 1):#遍历readfile()方法中读取到的内容
self.d.baidusousuo(getkeyword(i)) # 数据的参数化
try: # 以下断言的方式仅供参考,不具有实际意义
self.assertIn(getkeyword(i), self.driver.title)#断言输入的值是否和标题匹配
except Exception:
file_path=self.driver.get_screenshot_as_file('E://workspace//ModelAuto//imgaes//' + getkeyword(i) + '.png')#存放截图的路径
print('Screenshot_Path:图片路径', file_path)
logger.info(file_path);
time.sleep(2)
self.driver.back()#放回上一页
time.sleep(2)
if __name__=='__main__':#先执行自己的方法
unittest.main()
8、在testcase包中创建run_test.py文件用于生成测试报告
import unittest #导入系统自带的unittest
import HTMLTestRunner#导入HTMLTestRunner模块用于生成用例模板
import time#导入时间模块用于以时间生成用例报告
from ModelAuto.config import config
import sys
# 通过discover的方式把不同文件中的用例添加到测试套件(suite)中
def fun_suite():
# 指定测试用例所在的路径
test_dir= config.Run_FileURl #查找文件路径
suite = unittest.TestSuite()#使用unittest中的TestSuite()的方法
# 找到所有符合匹配规则的用例文件存入到discover变量中
discover = unittest.defaultTestLoader.discover(test_dir,pattern='Test*.py',top_level_dir=None)#查找以Test开头的文件
for dir in discover: # 遍历discover中的文件
for testcase in dir: # 遍历文件中的用例
suite.addTests(testcase) # 把用例添加到测试套件中
return suite
def report():
# 把时间添加到报告的名字里面
now = time.strftime('%Y_%m_%d_%H_%M_%S',time.localtime(time.time()))#公式化时间格式,得到想要的时间格式
filename = config.Run_FileURlRep+now+'.html'#存放用例报告的位置
fp = open(filename, 'w+', encoding='UTF-8')#创建文件方式 w+,格式UTF-8
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title="百度首页测试报告",description="用例执行情况:")#这个模板
runner.run(fun_suite())#运行自己的方法 run
report()
9、在public文件中创建logger.py日志文件,用来生成执行日志
import logging
import os.path
import time
class Logger(object):
def __init__(self, logger):
'''
指定保存日志的文件路径,日志级别,以及调用文件
将日志存入到指定的文件中
'''
# 创建一个logger
self.logger = logging.getLogger(logger)
self.logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
if not os.path.exists(log_path):
os.mkdir(log_path)
# print(os.getcwd()) # 获取当前工作目录路径
# print(os.path.abspath('.')) # 获取当前工作目录路径
# print(os.path.abspath(os.curdir)) # 获取当前工作目录路径
log_name = log_path + rq + '.log'
fh = logging.FileHandler(log_name,encoding="utf-8")
fh.setLevel(logging.INFO)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
# 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
self.logger.addHandler(fh)
self.logger.addHandler(ch)
def getlog(self):
return self.logger
# if __name__ == '__main__':
# Logger('模块名').getlog().info('dsds')
10、自定义截图函数
import time
import os
from selenium import webdriver
from pytetdom1.Logger.logger import Logger
logger=Logger(logger='浏览器启动').getlog() #如果使用logger.info("谷歌浏览器")使用这个
def screenshot(webdriver): #封装截屏函数
imageName=time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))# 用时间戳定义截图名称
imagepath=os.path.dirname(os.path.abspath('.'))+'\\imgaes\\'+imageName+'.png'
path = os.path.dirname(os.path.abspath('.'))+'\\imgaes\\' # 本地-保存截图地址
print(path)
if not os.path.exists(path): # 判断地址是否有效,如果不存在就创建一个地址
os.mkdir(path)
webdriver.get_screenshot_as_file(imagepath)
logger.info('lustrat' +'..\\imgaes\\'+ imageName + '.png' + 'luend')
print('lustrat' +'..\\imgaes\\'+ imageName + '.png' + 'luend') # 输出日志,前后加'luStrat'luEnd'特殊字符方便截取